
So You Are Uncomfortable with Duplicate Data?
If, like me, you’ve spent a reasonable amount of your career working with relational databases, where data is rationalised to avoid duplication, the idea of duplicating data across microservices is probably anathema to you.
Even if you’ve worked with a noSql database like MongoDB, where data is often duplicated across the documents, you probably still struggle with the idea of a service keeping a copy of data owned by another service.
Discomfort with duplication doesn’t need to come from databases. The Don't Repeat Yourself (DRY) principle of software engineering states that "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system". Even the process of Test Driven Development (TDD) includes a step for refactoring to remove duplication as part of the cycle.
As software developers we are programmed to detest duplication in all its forms.
It’s ok, I have felt your pain and as soon as you come to terms with the idea of duplicating data across microservices being the best way to make your microservices more robust, independent and decoupled from other services your pain will go - forever.
Making Microservices more Robust and More Independent
A Microservices architecture consists of a collection of different services which each provide a well defined, loosely coupled and independent business function. You can find out more at: https://microservices.io/. Let’s have a look at an example from part of a previous project of mine, an app for finding local cafes that serve great tea, called Find My Tea.
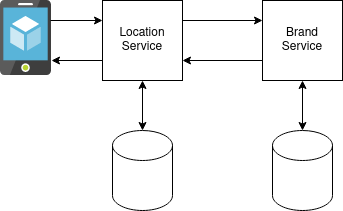
Find My Tea had a handful of microservices, but two of the most important ones were the Location service, which managed the locations (cafes, restaurants, etc.) where great tea could be found and the Brand service which managed the brands of tea served by the locations. Managing locations and brands consists of creating, reading, updating and deleting (CRUD) them. The Location service was the Single Source of Truth for Locations and the Brand service for brands.
In the first iteration, when the app requested a location, the Location service looked-up the location in its database, found the IDs of the brands served by location and then requested the details of those brands from the Brand service. The Brand service then looked up the brands in its database and passed them back to the Location service. The Location service then enriched the location with the brand details and passed it back to the app.
It is arguable that the more independent a microservice is, the more robust it becomes. Here we have a very clear dependency on the Brand service by the Location service when performing a location lookup request. If the Brand service is down or otherwise unavailable, either the brands are not returned with the location or, depending on how the location service is designed to handle partial failure, the entire request fails. There is also the potential latency of inter-service communication and two database lookups, although in a simple request such as this, it is likely to be negligible.
To remove this dependency the Location service can keep a copy of the data maintained by the Brand service up-to-date in its own database, so that when a location is requested, a call to the Brand service is not necessary. This does not make the Brand service redundant as it is still required to maintain the brand data and remains the Single Source of Truth for brands. The copy of the brand data kept in the Location service, although updatable from the Brand service, is effectively a read-only copy. The advantage is that if the Brand service is unavailable the location request will still succeed and the brand data will be present in the response.
Distribute the Data
However; this does beg the question of how to keep the brand data up-to-date in the Location service. Could this be a source of coupling? I’ve seen this done in two ways, but there are other approaches too.
One way is to have the Location service poll the Brand service every so often to get brand data and update it in its own database. There are a number of drawbacks with this approach. We all know polling is evil. In the case where you have multiple instances of the polling service, you have to specify one instance as the one that does the polling, or all of the instances could be polling for the data unnecessarily and all at the same time. The data in the Brand service may get updated in-between polls, meaning that the data is out of date, for a period of time, in the Location service - whatever method of data synchronisation you use, there will always be an element of Eventual Consistency. You either need to devise a clever mechanism for determining which brands have been updated since the last poll or always send back all of the data resulting in potentially large requests. The polling approach requires the Location service to know where to find the Brand service, creating an unnecessary dependency. It is also required to handle the error caused by the Brand service being down or unreachable. The polling approach doesn’t tend to scale very well for all of these reasons.
The approach I favour is to use a message broker. When a brand is created, updated or deleted, the Brand service can put a message onto a topic with only the details of that change. The Location service can listen to a queue, which is subscribed to the topic, and only update its database with a single brand when a message is received. There is no polling necessary. Message brokers are usually very fast and the amount of time the Location service would be out of date is likely to be negligible. The Location service only needs to know where the queue is that it is listening to. When there are multiple instances of the Location service, the queue can be configured to only deliver each message to the first instance which requests it. An added advantage is that the Brand service only needs to know where to find the topic. It doesn’t need to know anything about the Location service, or any other services, which may want to consume the messages via a queue subscribed to the topic. Of course both the sending and receiving services are slightly coupled by the format of the message and the data contract, potentially, becomes as important as any API contract.

More Robust, Independent and Loosely Coupled
It can be as simple as that. Maintaining a copy of data in one service, which is maintained by another service, can make the services more robust and independent. Distributing that data via a message broker makes the services loosely coupled, although not entirely decoupled, it keeps the data up-to-date and reduces the size of messages.
As with most things in software development, maintaining a local copy of data which is managed elsewhere is a tradeoff. As a software developer you must consider, for example, the security concerns which come with duplicating data. Especially if it is considered personal data. You must also consider the complexity of keeping the data up-to-date. For example, when does the data expire or become invalid. Does the data need to be versioned? Does the order of applied updates need to be taken into account?
I hope it goes without saying that in almost every other context duplication should still be avoided, detested and possibly even hated. However, it should also be clear that the trade off of duplicating data in microservices can make for better microservies.
Much of my early understanding of microservices, including the advantages of sharing data and some of the possible ways to do it came from Microservices Patterns by Chris Richardson (ISBN-13: 978-1617294549). If you’re interested in learning more about microservices, I would strongly recommend giving it a read. The rest has come from trial and error, failure, eventual success and quite a lot of arguing with colleagues.
Comments
Post a Comment